LPrincess's Emotion System
🫠基于语音的情感分析系统,详细代码在GitHub:https://github.com/L-mj0
0x01数据处理
这里我们使用的是RAVDESS数据集Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS),以及CREMA-D
关于数据集1
- RAVDESS 的这一部分包含 1440 个文件:每个演员 60 次试验 x 24 个演员 = 1440。RAVDESS 包含 24 名专业演员(12 名女性,12 名男性),用中性北美口音说出两个词汇匹配的语句。言语情绪包括平静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶等表情。每个表情都有两个情绪强度级别(正常、强烈),还有一个额外的中性表情。
- 文件命名规则:1440 个文件中的每一个都有唯一的文件名。文件名由 7 部分数字标识符组成(例如 03-01-06-01-02-01-12.wav)。这些标识符定义了刺激特征:
- 模态(01 = 全 AV,02 = 仅视频,03 = 仅音频)
- 语音通道(01 = 语音,02 = 歌曲)
- 情绪(01 = 中性、02 = 平静、03 = 快乐、04 = 悲伤、05 = 愤怒、06 = 恐惧、07 = 厌恶、08 = 惊讶)
- 情绪强度(01 = 正常,02 = 强烈)。注意:“中性”情绪没有强烈的强度
- 语句(01 =“孩子们在门边说话”,02 =“狗坐在门边”)
- 重复(01 = 第一次重复,02 = 第二次重复)
- 演员(01至24。奇数演员为男性,偶数演员为女性)
- 数据集来自:Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. .
数据集说明,文件命名第[7:8]为标签,因此,我们可以写一个文件处理把标签和wav文件提取出来
labels = []
data = []
subset_dirs_list = ['Actor_01', 'Actor_02', 'Actor_03', 'Actor_04', 'Actor_05', 'Actor_06', 'Actor_07', 'Actor_08']
# os.walk() 方法用于遍历文件夹的函数。成文件夹中每个子目录的路径 (dirname),子目录名列表 (dirs),以及文件名列表 (filenames)
for dirname, dirs, filenames in os.walk('archive/audio_speech_actors_01-24/'):
for filename in filenames:
labels.append(int(filename[7:8]) - 1)
wav_file_name = os.path.join(dirname, filename)
data.append(mfcc(wav_file_name))
关于数据集2——CREMA-D
这个数据集是各种各样的数据,有助于训练可以在新数据集上泛化的模型。许多音频数据集使用有限数量的说话者,这导致大量信息泄漏。 CREMA-D 有很多扬声器。事实上,CREMA-D 是一个非常好的数据集,可用于确保模型不会过度拟合。
CREMA-D 是一个数据集,包含来自 91 位演员的 7,442 个原始片段。这些片段来自 48 名男演员和 43 名女演员,年龄在 20 岁到 74 岁之间,来自不同的种族和民族(非裔美国人、亚洲人、白种人、西班牙裔和未指定的人种)。演员们从精选的 12 句话中进行发言。这些句子是使用六种不同情绪(愤怒、厌恶、恐惧、快乐、中性和悲伤)之一和四种不同情绪水平(低、中、高和未指定)来呈现的。
数据集中每种情绪统计:
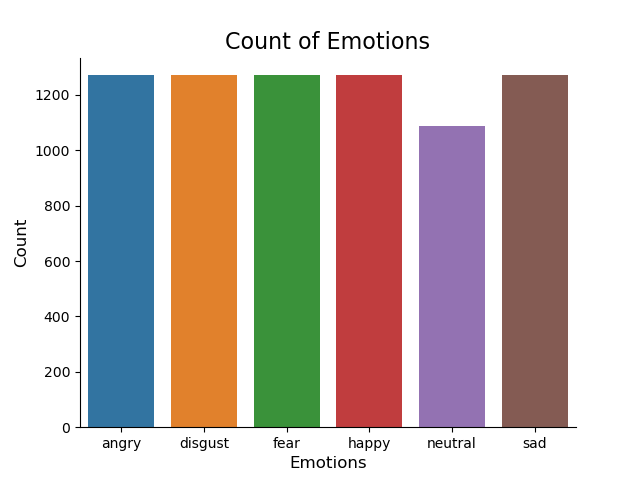
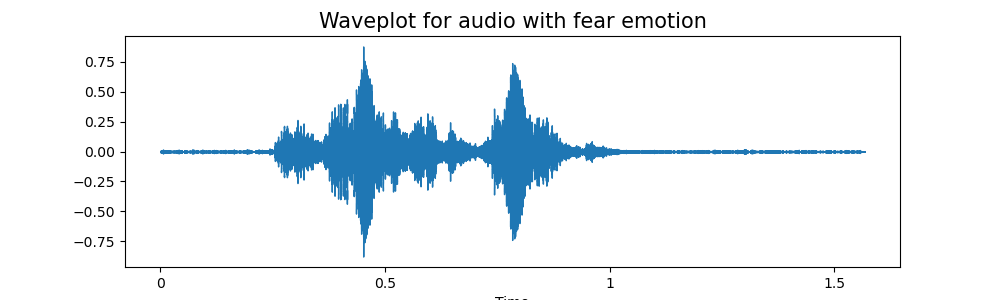
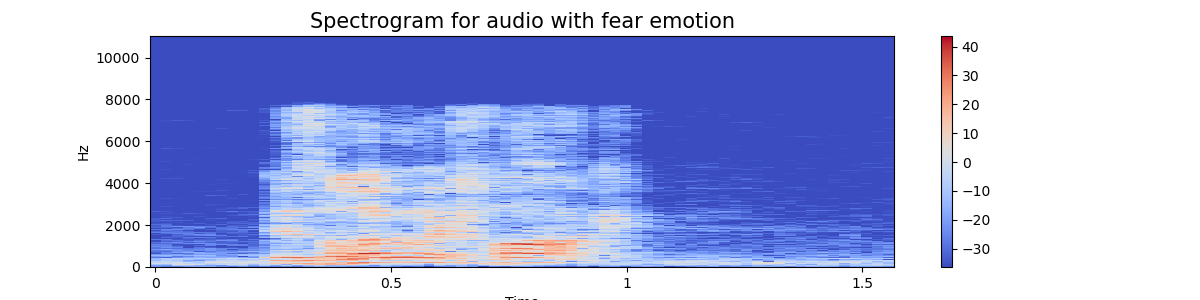
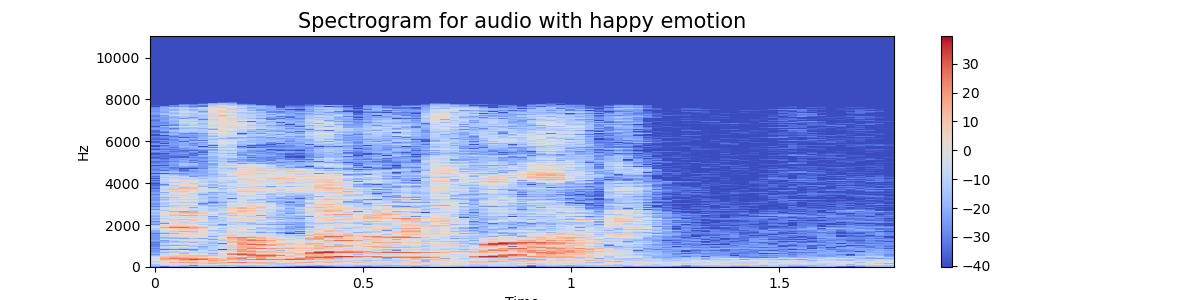
通过绘制每个情绪的音频信号的波图和频谱图
emotion='fear':
波图 - 波图让我们知道给定时间音频的响度
频谱图 - 频谱图是声音或其他信号随时间变化的频率频谱的直观表示。它表示给定音频/音乐信号的频率随时间变化的情况。
emotion='angry':
emotion='sad'
emotion='happy'
数据预处理
清洗、增强并去除音频数据集中的噪声
- 加载音频文件:使用Librosa加载音频文件。
- 降噪:应用降噪技术。
- 数据增强:应用时间位移、音调变化和速度变化等技术。
- 特征提取:从处理后的音频中提取MFCC特征。
- 标签提取:从文件名中提取标签。
语音文件处理:我们通过提取mfcc特征(MFCC(Mel-Frequency Cepstral Coefficients,梅尔频率倒谱系数)是对音频信号的短时功率谱进行线性余弦变换后得到的系数,通常用于捕捉音频信号的基本属性,如音调和音色)
def mfcc(wav_file_name):
# librosa.load() 用于加载音频文件,返回音频数据y,以及采样率sr
y, sr = librosa.load(wav_file_name)
# librosa.feature.mfcc()计算mfcc特征,n_mfcc为需要提取的mfcc数量 得到包含40个mfcc系数在整个音频信号上的均值的一维数组
mfccs = np.mean(librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40).T,axis=0)
return mfccs
下一步,就是将数据和标签转换为NumPy数组,且把标签转换成one-hot编码
例如标签为[0,1,2],则转换为
[[1,0,0]
[0,1,0]
[0,0,1]]
data_array = np.asarray(data)
label_array = np.array(labels)
# to_categroical() 将整数形式的标签转换为二进制的分类矩阵,即将整数标签转换为one-hot编码形式。
labels_categorical = to_categorical(label_array)
数据集处理完成后,进行分割训练集和测试集20%测试集,80%训练集
x_train,x_test,y_train,y_test = train_test_split(np.array(data_array),
labels_categorical,test_size = 0.2,random_state = 10)
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)
数据标准化是数据预处理的关键步骤,尤其是使用梯度下降等方法,这样可以加快模型训练的收敛,并提高模型性能
- StandarScaler()——将数据进行标准化,即减去均值并除以均值标准差,使得特征数据具有零均值和单位方差。
- fit_transform()——计算数据集的均值和标准差,并应用标准化;这里“拟合(fit)”指的是计算必要的转换参数(均值和标准差),“转换(transform)”则是应用这些参数来标准化数据。
- transform()——使用训练集上计算得到的均值和标准差来标准化测试集数据;⚠注意,这里没有使用 fit,因为我们使用的是训练集的参数。这是为了保证模型评估的准确性,确保模型在训练时没有接触到测试数据的任何信息。
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
数据增强——Crema
- 数据增强是我们通过在初始训练集上添加小扰动来创建新的合成数据样本的过程。
- 为了生成音频的句法数据,我们可以应用噪声注入、移动时间、改变音调和速度。
- 目标是使我们的模型对这些扰动保持不变并增强其泛化能力。
- 为了使其发挥作用,添加扰动必须保留与原始训练样本相同的标签。
- 在图像中,可以通过移动图像、缩放、旋转来执行数据增强......
首先,让我们检查哪些增强技术更适合我们的数据集。
- 简单音频
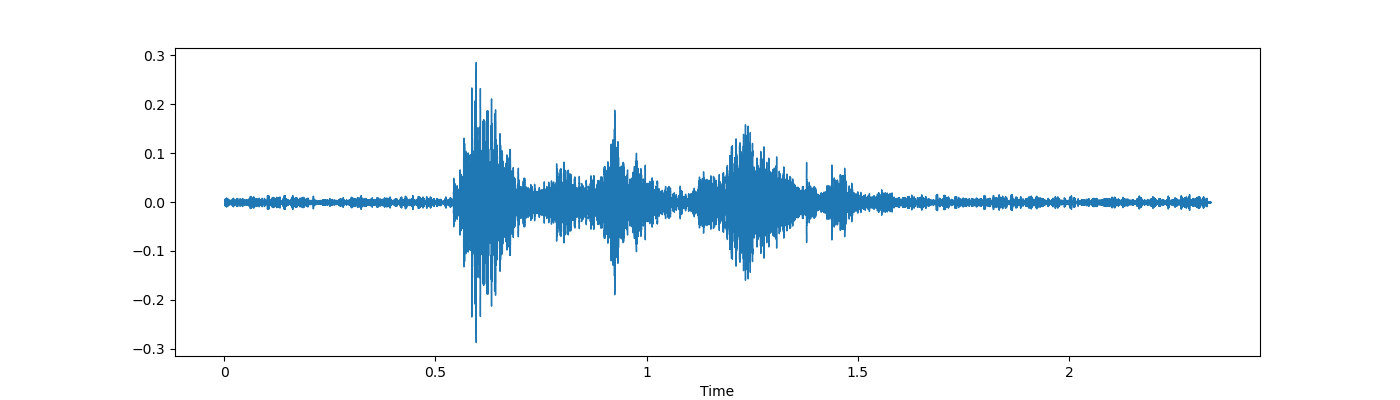
- 噪声注入 noise
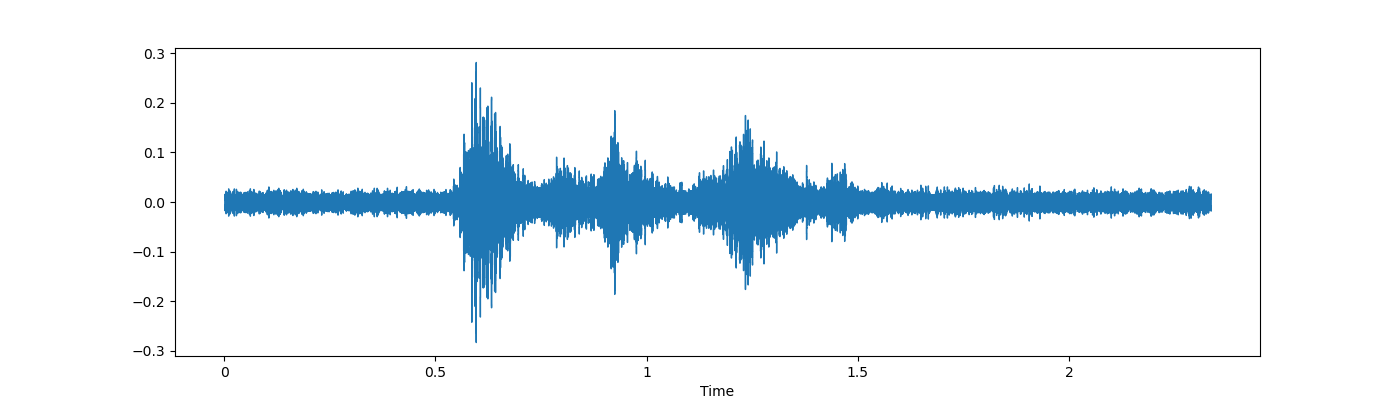
我们可以看到噪声注入是一种非常好的增强技术,因此我们可以确保我们的训练模型不会过度拟合
- 拉伸 stretching
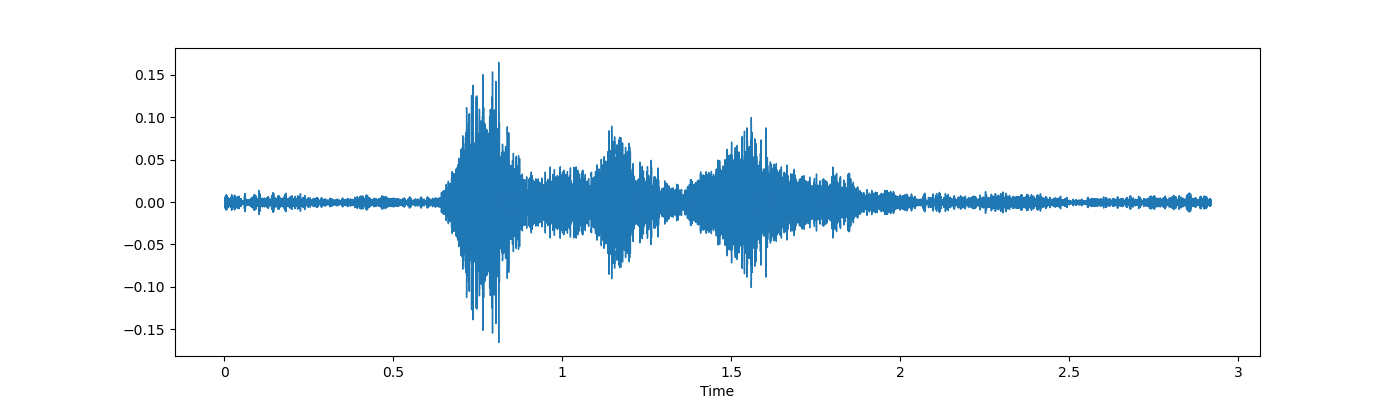
- 转移 shift
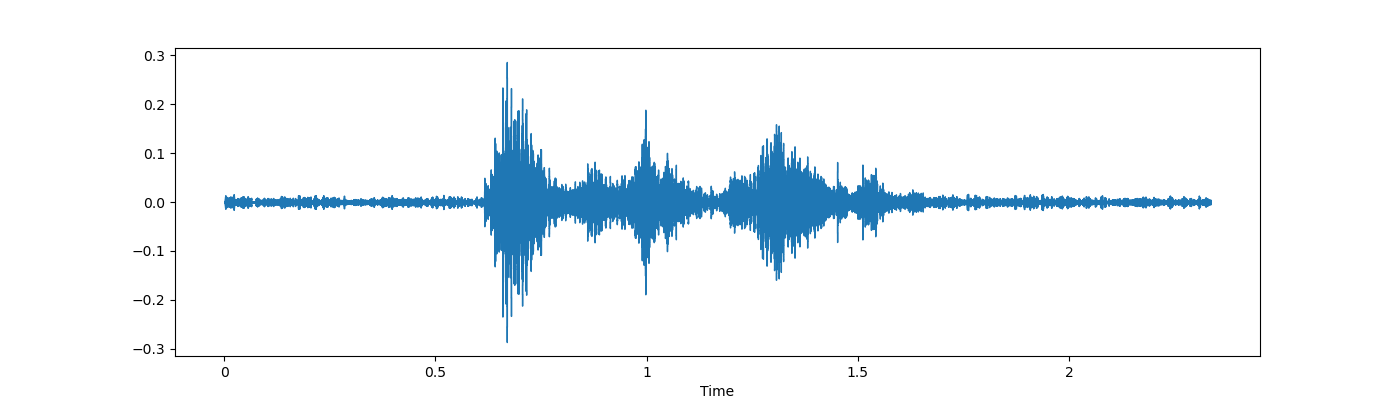
- Pitch——音高
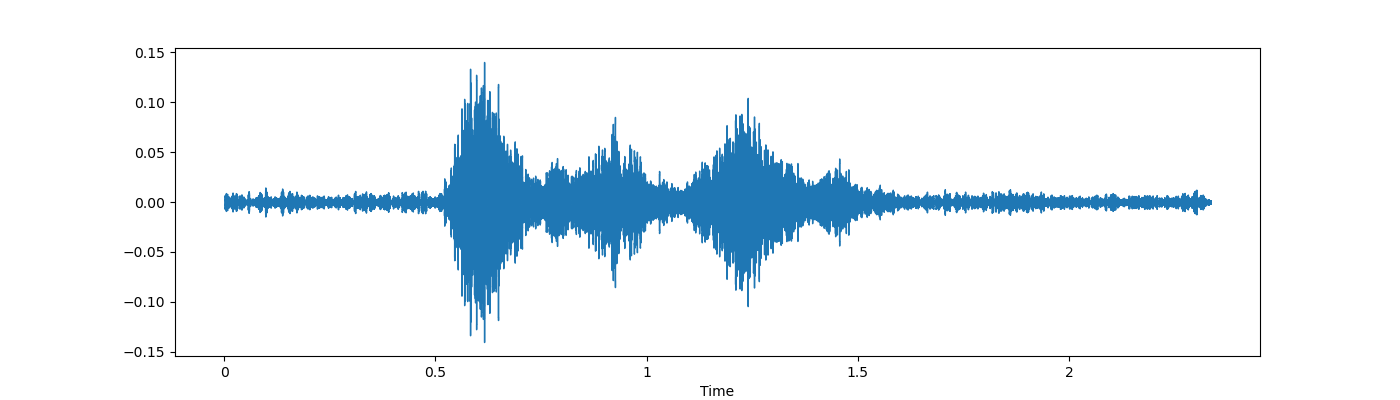
从上述类型的增强技术中,我使用了噪音、拉伸(即改变速度)和一些俯仰。
特征提取
特征提取是分析和寻找不同事物之间关系的一个非常重要的部分。我们已经知道,模型无法直接理解音频提供的数据,因此我们需要将它们转换为可理解的格式,以便使用特征提取。
音频信号是三维信号,其中三个轴分别代表时间、幅度和频率。
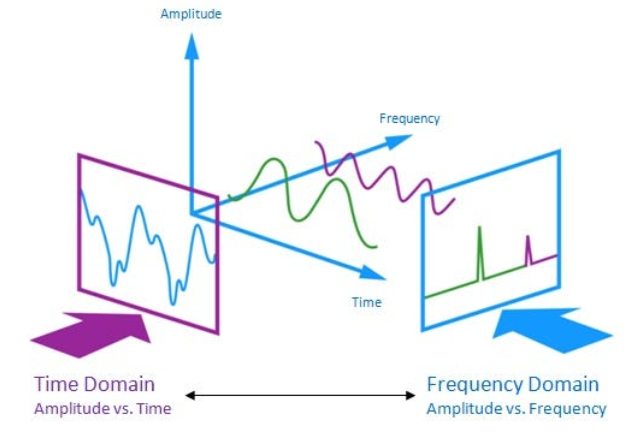
如前所述,借助采样率和样本数据,可以对其执行多次转换以从中提取有价值的特征。
- 过零率:特定帧持续时间内信号符号变化的速率。
- 能量:信号值的平方和,通过相应的帧长度进行归一化。
- 能量熵:子帧归一化能量的熵。它可以被解释为突然变化的度量。
- 光谱质心:光谱的重心。
- 频谱扩展:频谱的第二中心矩。
- 谱熵:一组子帧的归一化谱能量的熵。
- 光谱通量:两个连续帧的光谱归一化幅度之间的平方差。
- 频谱滚降:频谱的 90% 幅度分布集中在低于该频率的频率。
- MFCC 梅尔频率倒谱系数形成倒谱表示,其中频带不是线性的,而是根据梅尔尺度分布。
- 色度向量:频谱能量的 12 元素表示,其中容器代表西方音乐的 12 个等律音级(半音间距)。
- 色度偏差:12 个色度系数的标准偏差。
在这里我们只提取5个特征:
Zero Crossing Rate 过零率 Chroma_stft 色度_stft MFCC 微流控催化裂化 RMS(root mean square) value RMS(均方根)值
这里print(len(X), len(Y), Crema_df.Path.shape)
22326 22326 (7442,)
来训练我们的模型且应用了数据增强并提取了每个音频文件的特征并保存它们。
数据准备
- 选择特征和标签:
- X:从Features数据框中提取除最后一列(标签列)之外的所有列作为特征。
- Y:提取labels列作为预测标签。
- 标签编码(One-Hot Encoding):
- 使用OneHotEncoder将类别标签转换为一热编码形式。这是因为多分类问题中的神经网络通常需要目标变量的一热编码形式。
- 拆分数据集:
- 使用train_test_split将数据分为训练集和测试集。random_state确保每次代码运行时拆分都相同,以便可复现。shuffle=True表示在拆分之前将数据随机打乱。
- print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
(16744, 162) (16744, 6) (5582, 162) (5582, 6)
- 特征标准化:
- 使用StandardScaler对特征进行标准化(即,平均值为0,方差为1的正态分布)。这是因为大多数神经网络模型都假设输入数据是标准化的。
- 调整数据维度:
- 增加一个维度,以适应神经网络期望的输入形状。对于某些类型的深度学习模型(例如卷积神经网络),可能需要将输入数据调整为3D形状。这里通过np.expand_dims在第二维度(axis=2)上增加一维。
- print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
(16744, 162, 1) (16744, 6) (5582, 162, 1) (5582, 6)
0x02模型训练——[Keras]MLP(多层感知器)
Keras
说到深度学习,不可避免得会提及业界有哪些优秀的框架,Keras神经网络框架便是其中之一,它是一个高级神经网络APl,用Python编写,能够在TensorFlow,CNTK或Theano之上运行。
# GPU版本
conda install keras-gpu
# CPU版本
conda install keras
MLP
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
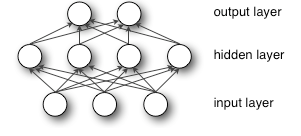
从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
MLP的输入层X其实就是我们的训练数据,所以输入层不用实现,剩下的就是“输入层到隐含层”,“隐含层到输出层”这两部分。上面介绍原理时已经说到了,“输入层到隐含层”就是一个全连接的层,在下面的代码中我们把这一部分定义为HiddenLayer。“隐含层到输出层”就是一个分类器softmax回归(也有人叫逻辑回归),这一部分定义为LogisticRegression。
主要参数
hidden_layer_sizes:一个元组,其中的整数表示每个隐藏层中的神经元数量。在这里,(300,) 表示有一个隐藏层,包含300个神经元。
activation:{‘identity’, ‘logistic’, ‘tanh’, ‘relu’} 隐藏层使用的激活函数
| 参数 | 激活函数数学表达式 |
|---|---|
| identity | f(x) = x |
| logistic | f(x) = 1 / (1 + exp(-x)) |
| tanh | f(x) = tanh(x) |
| relu | f(x) = max(0, x) |
solver:权重优化方法
| 参数 | 描述 |
|---|---|
| lbfgs | 一种拟牛顿法优化方法 |
| sgd | 随机梯度下降方法 |
| adam | 一种基于随机梯度的优化方法 |
对于大型数据集(训练数据集有上千个数据),“adam”方法不管是在训练时间还是测试集得分方面都有不俗的表现,但是对于小型数据集,“lbfgs”能够有更快的收敛速度而且表现得更好
alpha:float,0.0001,L2惩罚(正则化项)参数。正则化可以帮助防止模型过拟合训练数据。较大的值意味着更强的正则化。
batch_size:int,“auto”,mini_batch大小,每次梯度更新的样本数。
- 如果使用“lbfgs”分类器将不会有mini_batch
- 如果使用“auto”,该参数值batch_size=min(200, n_samples)
- 当使用随机梯度下降优化算法(SGD)时,batch_size决定了每个批次中的样本数量。
learning_rate:{‘constant’, ‘invscaling’, ‘adaptive’},’constant’,学习率更新方法:
| 参数 | 描述 |
|---|---|
| constant | 学习率保持恒定,值由参数"learning_rate_init"提供 |
| invscaling | 使用一个逆指数(power_t)在每个时间步长t1逐渐减小学习率,保持效率最高的学习率:effective_learning_rate = learning_rate_init / pow(t, power_t) |
| adaptive | 只要训练损失不断减小,就保持学习率不变,如果连续两次迭代所减低的训练损失小于n(n=tol)或者提高的验证得分小于n(n=tol)当参数early_stopping=True时2,学习率将处除以5 |
max_iter:最大迭代次数,代表epoch,即每个数据将会被使用多少次,权重优化方法将会一直迭代直到收敛或者达到迭代次数。
epoch是一个单位,一个epoch代表训练模型时所有训练数据均被使用过一次的更新次数,比如如果训练数据集有10000条训练数据,用大小为100的mini_batch进行学习时,重复随机梯度下降100次,此能保证所有数据都被使用了一遍,我们称100次就是一个epoch
类方法
fit(X, y):使用数据X和标签y进行拟合
get_params([deep]):获取模型参数
partial_fit(X, y[, classes]):使用给定数据对数据进行一次迭代
predict(X):预测未知数据的标签
score(X, y[, sample_weight]):获取给定数据和标签的平均精度(用数据给模型评分)
set_params(**params):设置模型参数
model = MLPClassifier(alpha=0.1, batch_size=256, epsilon=1e-08,
hidden_layer_sizes=(300,), learning_rate='adaptive',
max_iter=1000,verbose=True)
对训练完的模型,拟合操作,绘制Loss曲线
history = model.fit(x_train, y_train)
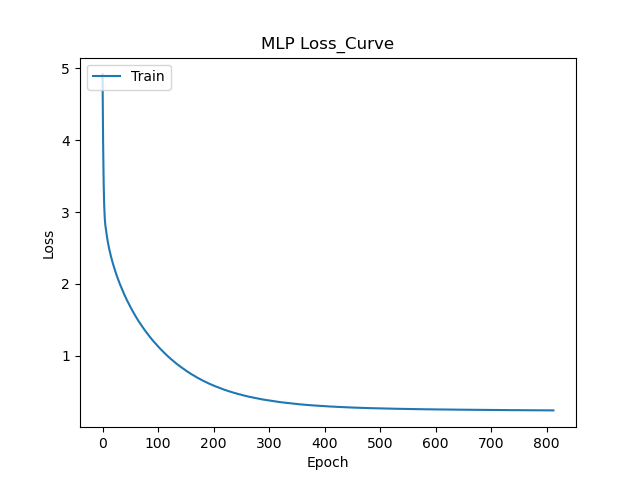
最后保存模型以及标准化器:
# 保存模型
joblib.dump(model, 'model_mlp.pkl')
# 保存标准化器
joblib.dump(scaler, 'scaler_mlp.pkl')
0x03模型训练——LSTM
LSTM 是一种特殊的循环神经网络(RNN),非常适合于时间序列数据或者序列数据的处理,如语音数据。在情感分析任务中,特别是利用音频特征(如 MFCC),LSTM 能够捕获语音的时间动态特性。
RNN
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
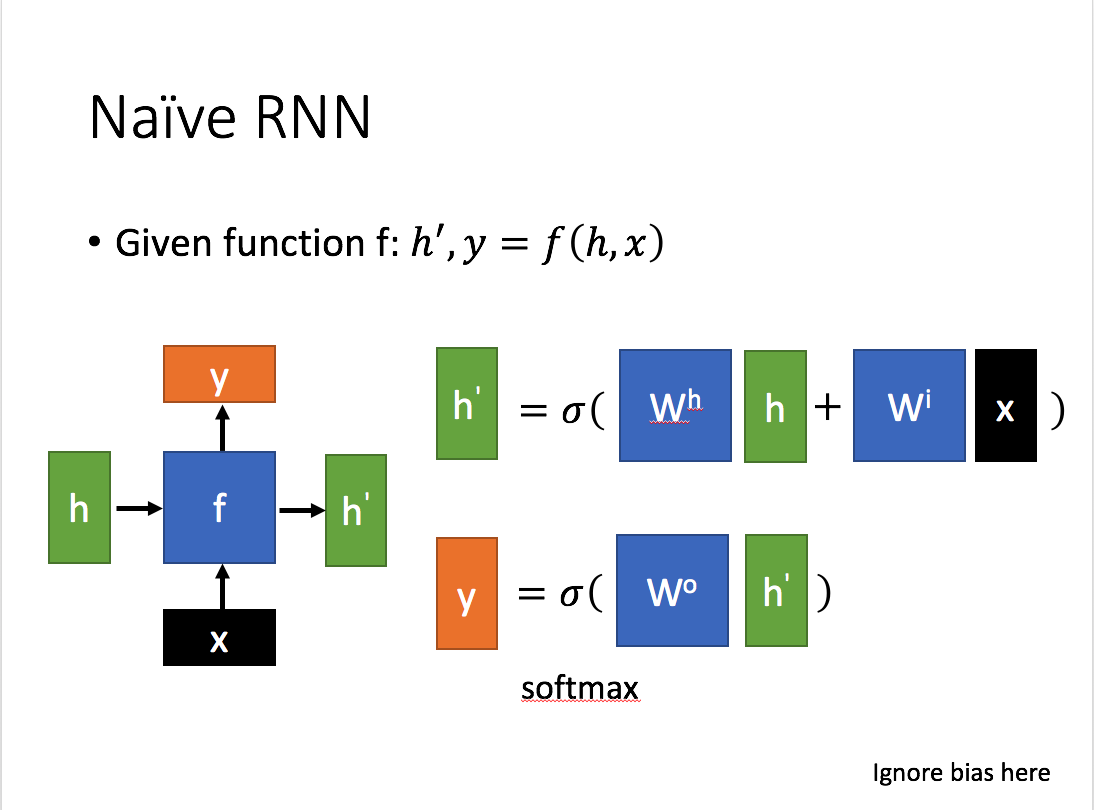 这里,
这里,
x代表当前状态下数据的输入,h代表接收到上个节点的输出
y为当前节点状态下的输出,h'代表传递到下个节点的输出。
y常常使用h'投入到一个线性层(主要是维度映射),使用softmax进行分类得到需要的数据,通过序列形式的输入,就能得到以下形式的RNN:
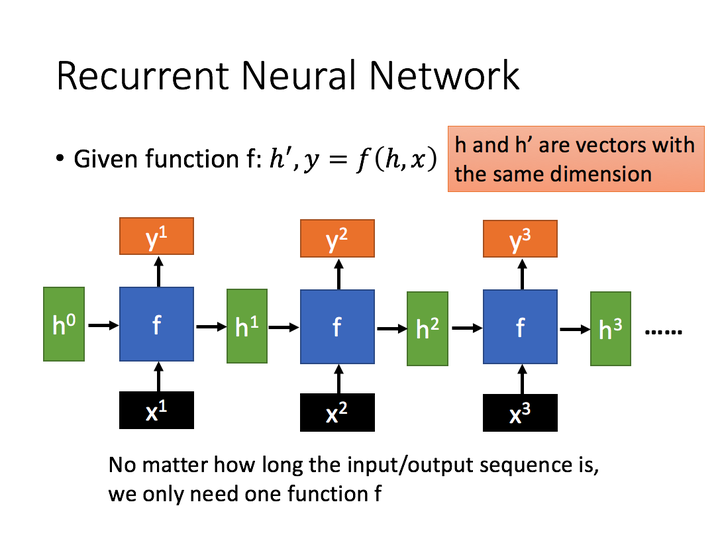
LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,引入了一个复杂的单元结构,称为LSTM单元,它包含四个交互的组件:遗忘门、输入门、细胞状态和输出门。这些组件共同工作,允许LSTM单元记住长期依赖并忘记不重要的信息。能够解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
Tips
什么是梯度消失: 在深度网络的反向传播过程中,误差梯度(用于更新权重)随着层数增加而逐渐变小,最终接近于零。这导致靠近输入层的权重几乎不更新,使得网络难以学习。
什么是梯度爆炸: 在深度网络的反向传播过程中,误差梯度越积越大,最终变得非常大。这可能会导致权重更新过大,使得网络权重变得非常大或者不稳定,从而导致网络无法学习或者数值计算问题。
如何解决?
对于梯度消失: 可以使用ReLU激活函数代替Sigmoid或Tanh,或者使用LSTM等门控循环单元来缓解这一问题。
对于梯度爆炸: 通常通过梯度裁剪(限制梯度的大小)或者调整学习率等策略来控制。
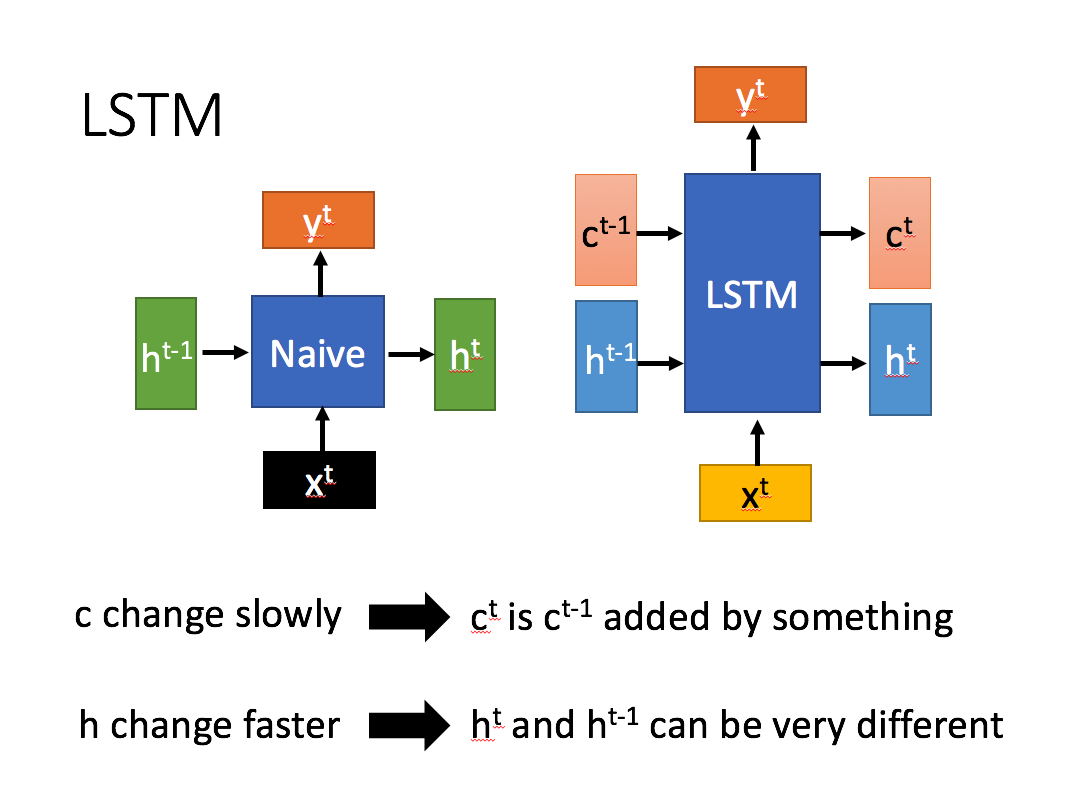
左边是普通RNN,右边是LSTM结构
相比RNN只有一个传递状态ht,LSTM有两个传输状态,一个ct(cell state),和一个h^t(hidden state)。
对于传递下去的ct改变的很慢,通常输出的ct是上一个状态传过来的ct-1加上一些数值。而ht则在不同节点下往往会有很大区别
主要区别就是LSTM结构多了一个c^t细胞状态,它在网络中流动并且只受到少数门的影响,这使得信息能够不受太大影响地在时间上进行传递。传统RNN没有这样的机制。
- 重要代码部分
extract_mfcc(wav_file_name): 这个函数对给定的音频文件进行处理,提取 MFCC 特征。
create_LSTM(): 这个函数创建了一个 LSTM 网络结构,用于情感识别任务。
- Sequential(): 创建一个线性堆叠的模型,一个空的序列模型,即模型的各层是线性排列的。
- 第一层是 LSTM 层,有128个单元,输入形状是(40,1),这里的 128 表示 LSTM 层中的单元数或神经元数。return_sequences=False 意味着这个 LSTM 层只会返回最后一个输出,适用于只有一个输出节点的情况(如分类问题)。input_shape=(40, 1) 定义了每个输入数据的形状,即每个样本输入有40个时间步,每个时间步有1个特征。
- model.add(Dense(64, activation='relu')): 添加一个密集连接(全连接)层,有64个神经元,激活函数为ReLU。这是分类器的一部分,用于从LSTM层提取的特征中学习。
- model.add(Dropout(0.3)): 添加一个 Dropout 层,随机丢弃 30% 的节点,防止过拟合。
- model.add(Dense(32)) 和 model.add(Dense(8)): 进一步添加密集连接层,逐步减少神经元的数量,最终转换到输出类的大小。
- 最后是一个8单元的Dense层,使用 softmax 激活函数,因为这是一个多类分类问题,通常情感分析会有多种情感标签。
- 在模型定义的最后,使用 compile 方法编译模型,指定损失函数为 categorical_crossentropy(用于多类分类),优化器为 adam,以及评估模型性能的指标为准确率(accuracy)。
model.fit(): 这是模型训练的核心步骤,通过给定的训练数据和标签,网络通过反向传播算法学习特征与情感之间的映射关系。
- 使用 model.fit() 方法来训练模型。此处将数据集的前一部分指定为训练数据,剩余部分为验证数据。
- np.expand_dims(data_array[:training_samples], axis=-1) 是将训练数据转换为模型期望的输入格式。data_array 包含了所有的输入特征(这里是MFCC特征)。expand_dims 是在数组的最后一个轴上增加一个维度,因为 LSTM 期望三维输入(样本数,时间步长,特征数)。
- labels_categorical[:training_samples]: 这是训练数据的标签,已经被转换为分类格式(one-hot encoding)。
- validation_data=(...): 这部分提供了验证数据集。验证数据同样是通过 np.expand_dims 方法处理的MFCC特征和对应的标签。这些数据用来评估模型在未见过的数据上的表现,帮助监控和调整模型,如防止过拟合。
- epochs=1000 表示模型将遍历全部数据1000次。一个epoch意味着整个输入数据的单次向前和向后传递。
- shuffle=True 在每个epoch开始时,训练数据会被随机打乱。这有助于模型学习更泛化,防止对训练集样本顺序的依赖。
plt.plot(): 用于可视化训练过程中损失和准确率的变化,帮助监控模型训练状态。
def create_LSTM():
model = Sequential()
model.add(LSTM(128, return_sequences=False, input_shape=(40, 1)))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Activation('relu'))
model.add(Dense(32))
model.add(Dropout(0.3))
model.add(Activation('relu'))
model.add(Dense(8))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
history = model.fit(np.expand_dims(data_array[:training_samples], axis=-1),
labels_categorical[:training_samples],
validation_data=(
np.expand_dims(data_array[training_samples:training_samples + validation_samples], axis=-1),
labels_categorical[training_samples:training_samples + validation_samples]), epochs=1000,
shuffle=True)
0x04 模型训练——双向LSTM
这个模型是一个改进后的长短时记忆网络(LSTM),专门用于情感分析,即识别语音的情绪。LSTM 是循环神经网络(RNN)的一种,特别适用于序列数据的学习,例如语音、文本或时间序列数据。
双向卷积神经网络的隐藏层要保存两个值, A 参与正向计算, A' 参与反向计算。 最终的输出值 y 取决于 A 和 A':
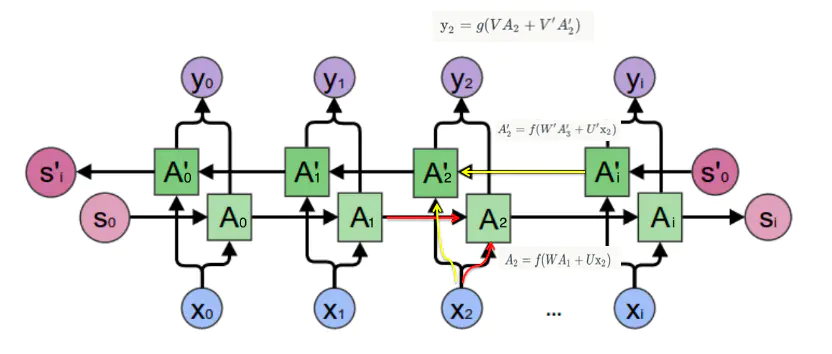
正向计算时,隐藏层的 s_t 与 s_t-1 有关;反向计算时,隐藏层的 s_t 与 s_t+1 有关:
该模型结构和实现原理如下:
Sequential Model:
Sequential是 Keras 中的一个模型,它提供了一系列线性堆叠的层。这意味着你可以通过.add()方法依次添加层。Bidirectional LSTM Layer:
- 第一层是一个双向LSTM层,它的作用是捕捉序列数据(语音帧)中的前后依赖关系。每个LSTM单元输出128个特征。
- 该层设置了
return_sequences=True,使得LSTM层输出所有时间步的隐藏状态,为下一层双向LSTM提供完整序列信息。 - 第二个双向LSTM层有64个单元,它进一步处理第一层的输出。这里
return_sequences=False,使得这层只返回序列的最后一个输出,为后面的全连接层做准备。
- Dense Layer with L2 Regularization:
- 接下来是全连接层(Dense Layer),有64个神经元,并使用relu激活函数。这层用于学习高级特征。
- 此层引入了L2正则化(通过kernel_regularizer=l2(0.01))。L2正则化可以防止模型过拟合,增强模型的泛化能力。0.01是正则化的系数,控制正则化的强度。
Dropout Layer:
Dropout(0.5)意味着在训练过程中每次更新参数时随机断开50%的输入神经元连接。这是防止过拟合的又一技术,能够有效提升模型的泛化能力。Activation Layer: 再次使用
relu激活函数进一步引入非线性,使得网络可以学习更加复杂的特征。Output Layer: 最后是一个有8个神经元的全连接层,对应8种情绪状态,使用softmax激活函数。Softmax确保输出值是概率分布,总和为1,每个神经元的输出可以解释为属于对应情绪的概率。
label = ['neutral', 'calm', 'happy', 'sad', 'angry', 'fearful', 'disgust', 'surprised']
- Compile the Model:
- 模型使用
categorical_crossentropy作为损失函数,这是多分类问题常用的损失函数。 adam优化器是一种效果广泛认可的优化算法,它动态调整学习率,适用于大多数情况。- 模型以
accuracy为指标来评估性能。
主要代码部分:
def create_LSTM():
model = Sequential()
# 双向LSTM
model.add(Bidirectional(LSTM(128, return_sequences=True, input_shape=(40, 1))))
model.add(Bidirectional(LSTM(64, return_sequences=False)))
# 增加l2正则化
model.add(Dense(64, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dropout(0.5))
model.add(Activation('relu'))
model.add(Dense(32, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dropout(0.5))
model.add(Dense(8, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
通过双向LSTM的结构,模型能够更好地捕捉语音数据中的时间关系,而正则化和Dropout则有助于避免过拟合,使模型在未见过的数据上表现更好。这种结构对于处理和理解序列数据,尤其是在情感分析等领域中非常有效。
def create_LSTM():
model = Sequential()
# 双向LSTM
model.add(Bidirectional(LSTM(128, return_sequences=True, input_shape=(40, 1))))
model.add(Bidirectional(LSTM(64, return_sequences=False)))
# 增加l2正则化
model.add(Dense(64, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dropout(0.5))
model.add(Activation('relu'))
model.add(Dense(32, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dropout(0.5))
model.add(Dense(8, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
但是该代码最终跑出来的模型,呈现明显过拟合状况
36/36 [==============================] - 1s 26ms/step - loss: 0.4308 - accuracy: 0.9227 - val_loss: 5.4263 - val_accuracy: 0.2292
5/5 [==============================] - 0s 10ms/step - loss: 3.9044 - accuracy: 0.3611
- 训练过程:
36/36 [==============================]: 这表示在训练集上进行了36批次(batches)的迭代。每个批次都成功地完成了。loss: 0.4308: 训练数据上的损失(loss)已降至0.4308。损失越低,模型在训练数据上的拟合越好。accuracy: 0.9227: 训练数据的准确率为92.27%,这是一个相对较高的准确率,表明模型在训练数据上能够很好地进行预测。
- 验证过程:
val_loss: 5.4263: 验证集上的损失显著高于训练集。这通常是过拟合的一个迹象,意味着模型在训练数据上表现得很好,但没有很好地泛化到新数据上。val_accuracy: 0.2292: 验证集上的准确率只有22.92%,与训练准确率相比差距很大,进一步确认了过拟合的可能性。
- 测试过程:
5/5 [==============================]: 在测试集上进行了5批次的迭代。loss: 3.9044: 测试集的损失。accuracy: 0.3611: 测试集的准确率为36.11%,比验证集有所提高,但仍远低于训练集的准确率。
问题分析及改进
- 过拟合:
- 该模型在训练集上表现出高准确率,但在验证集和测试集上准确率显著下降,这是过拟合的典型迹象。
- 解决方案包括:
- 更多的数据:如果可能,提供更多的训练数据。
- 数据增强:对现有数据进行变换以生成更多样本。
- 正则化:使用L1、L2或Dropout等正则化技术减少过拟合。
- 减少模型复杂度:简化模型的架构可能有助于减少过拟合。
- 模型调优:
- 调整模型参数,如学习率、批次大小、LSTM单元数量等,可能会改善性能。
- 尝试不同的优化器如Adam、SGD等。
- 评估指标:
- 除了准确率外,也可以考虑其他评估指标,如F1分数、召回率和精确率,特别是在类别不平衡的情况下。
- 早停(Early Stopping): 当验证损失不再下降时停止训练,以避免过度拟合。
针对以上问题分析,我对模型进行了改进
- LSTM层也添加L2正则化。
model.add(Bidirectional(LSTM(128, return_sequences=True, input_shape=(40, 1), kernel_regularizer=l2(0.01))))
model.add(Bidirectional(LSTM(64, return_sequences=False,kernel_regularizer=l2(0.01))))
- 调整Dropout率可以帮助改进模型
model.add(Dropout(0.6)) - 减少模型复杂度,删除
model.add(Activation('relu')) - 使用早停来防止过度训练。当验证集的损失停止改进时停止训练。
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=20, restore_best_weights=True)
0x06 模型训练——CNN
定义了一个一维卷积神经网络(Conv1D)。
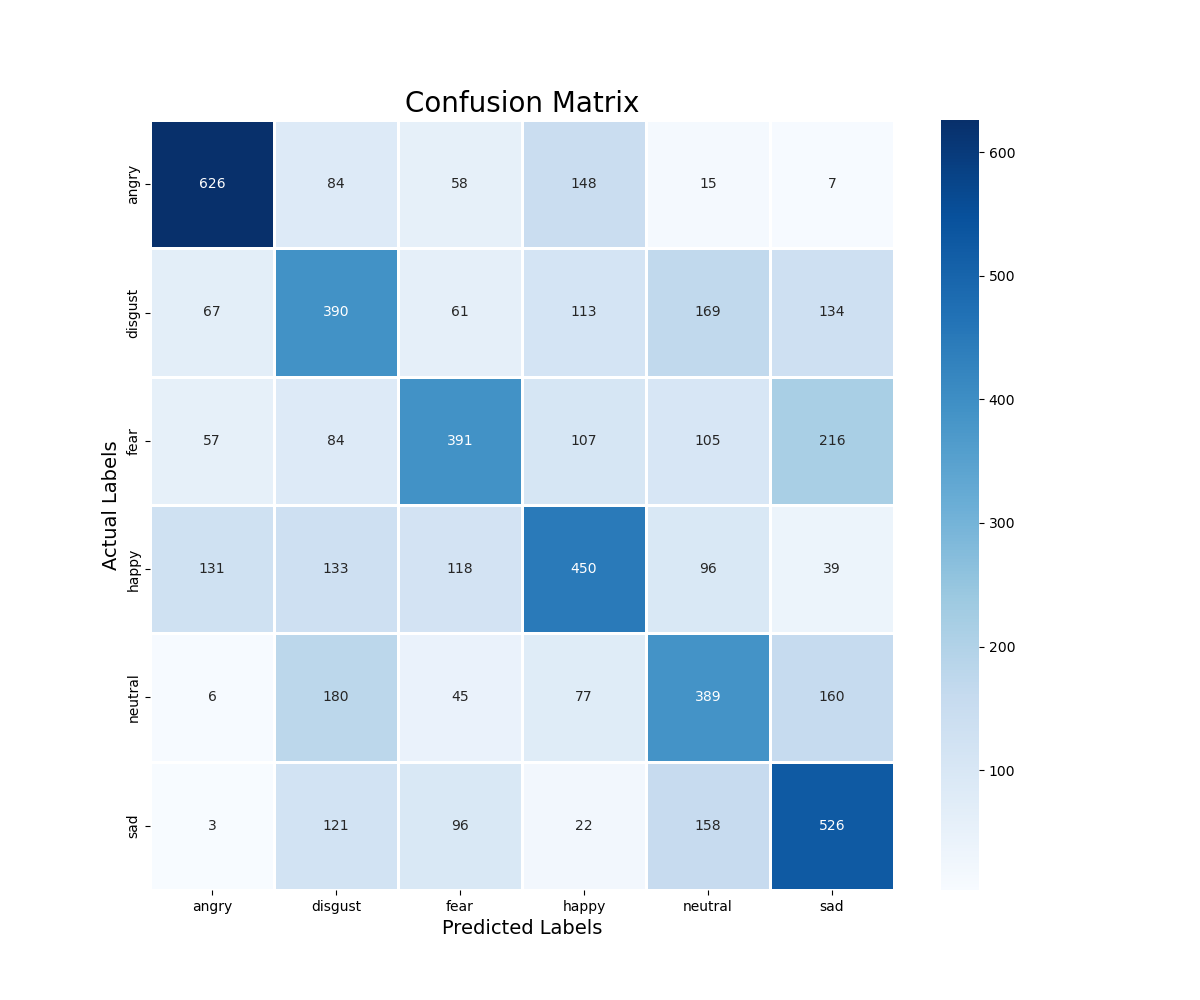
['angry','disgust','fear','happy','neutral','sad']
网络结构:
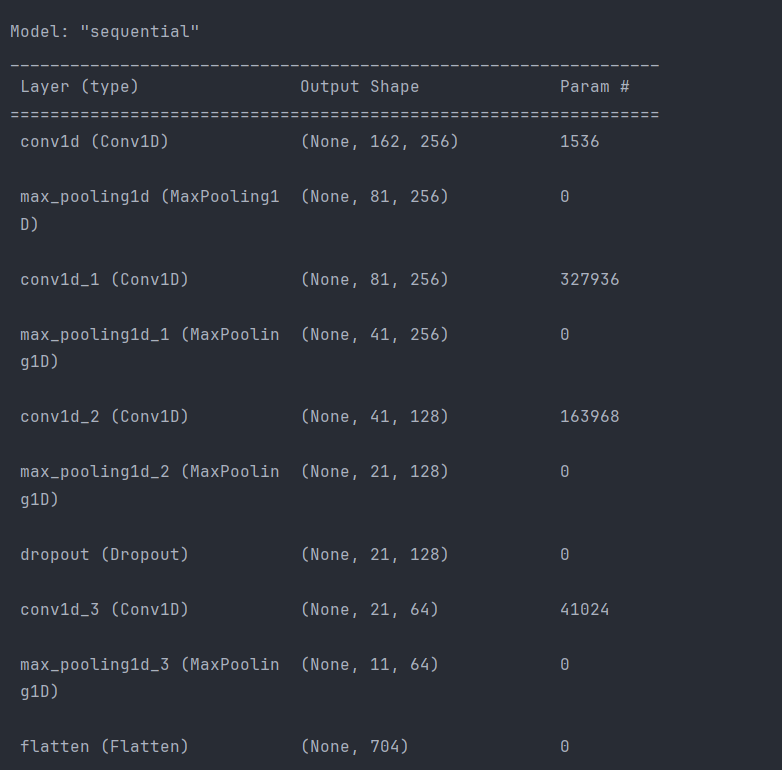
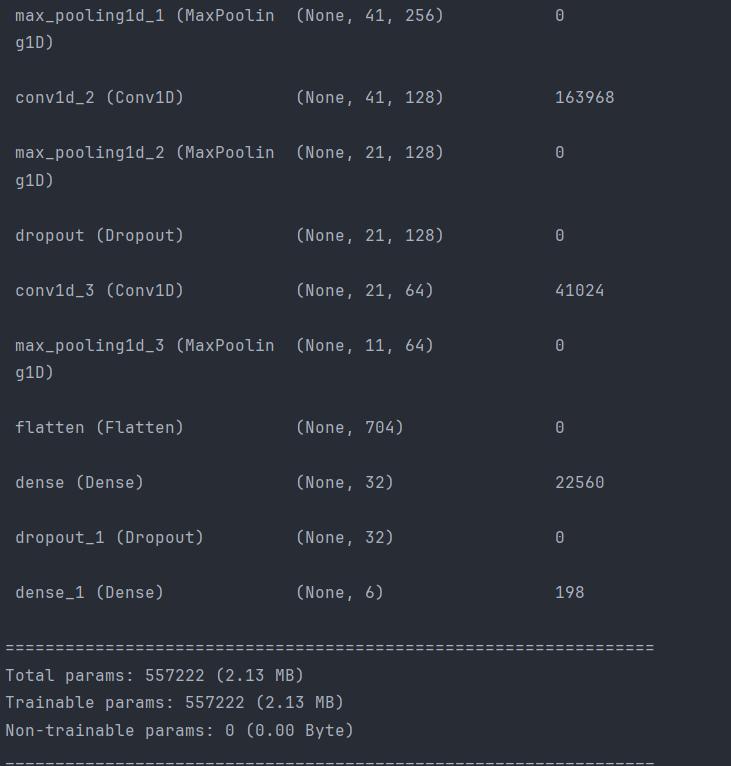
以下是自定义模型结构说明:
- Sequential模型:使用Sequential模型,这种方式按顺序一层层地堆叠模型。
- 第一层:Conv1D
- 添加一个Conv1D层,有256个滤波器,每个滤波器的核大小是5,步长为1,padding方式为'same'(边界填充),激活函数是ReLU。输入形状是(x_train.shape[1], 1),其中x_train.shape[1]是特征的数量。
- MaxPooling1D:
- 添加MaxPooling1D层以减少模型参数和计算量,池化大小为5,步长为2,padding方式为'same'。
- 更多的Conv1D和MaxPooling1D层:
- 再添加几个Conv1D和MaxPooling1D层,逐渐减小滤波器的数量,并在每次卷积之后进行池化。
- Dropout层:
- 添加Dropout层以防止模型过拟合,随机丢弃一些神经元的输出。
- Flatten层:
- 使用Flatten层将多维输入一维化,准备连接到全连接层(Dense)。
- Dense层:
- 添加两个Dense层,第一个用ReLU激活函数,32个单元;第二个是输出层,用Softmax激活函数,有8个单元,对应8种情感分类。
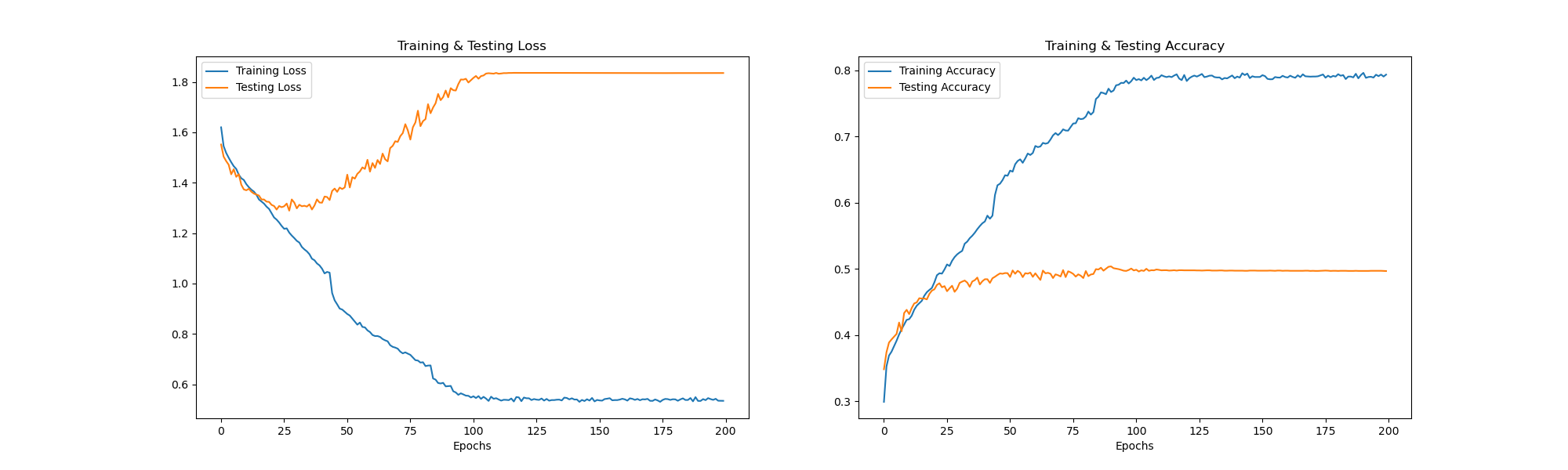
训练200轮次:

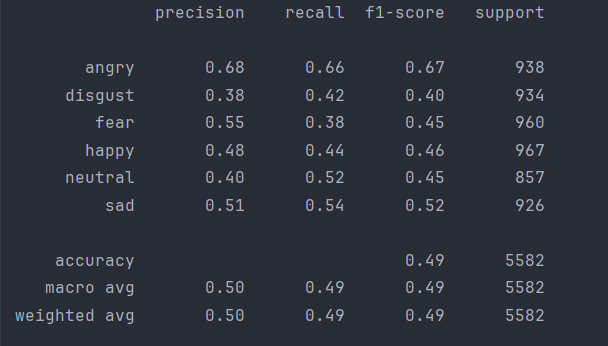
0x07 模型训练与评估
通过回调函数动态调整学习率来提高模型的性能,最后评估并打印出模型在测试数据上的准确率。
- ReduceLROnPlateau:
- ReduceLROnPlateau是一个回调函数,用于在模型训练过程中根据验证损失减小学习率,以提高模型的训练效果。这里,它监控的是loss(训练损失),当训练损失在2个epoch内没有改善时,将学习率乘以0.4。min_lr设为0.0000001,意味着学习率的下限是0.0000001。
- 模型训练:
- 使用model.fit()方法训练模型,传入训练数据x_train和y_train,批量大小为64,训练50个周期。同时,将x_test和y_test作为验证数据集,每个周期结束后,模型会在这些数据上评估其性能。callbacks=[rlrp]表明将上面定义的ReduceLROnPlateau回调函数应用于训练过程,以动态调整学习率。
- 性能评估:
- 使用model.evaluate()在测试数据x_test和y_test上评估模型性能。该方法返回损失值和准确率。这里提取准确率(索引为1的返回值),并将其乘以100转换为百分比形式,打印出模型在测试数据上的准确率。
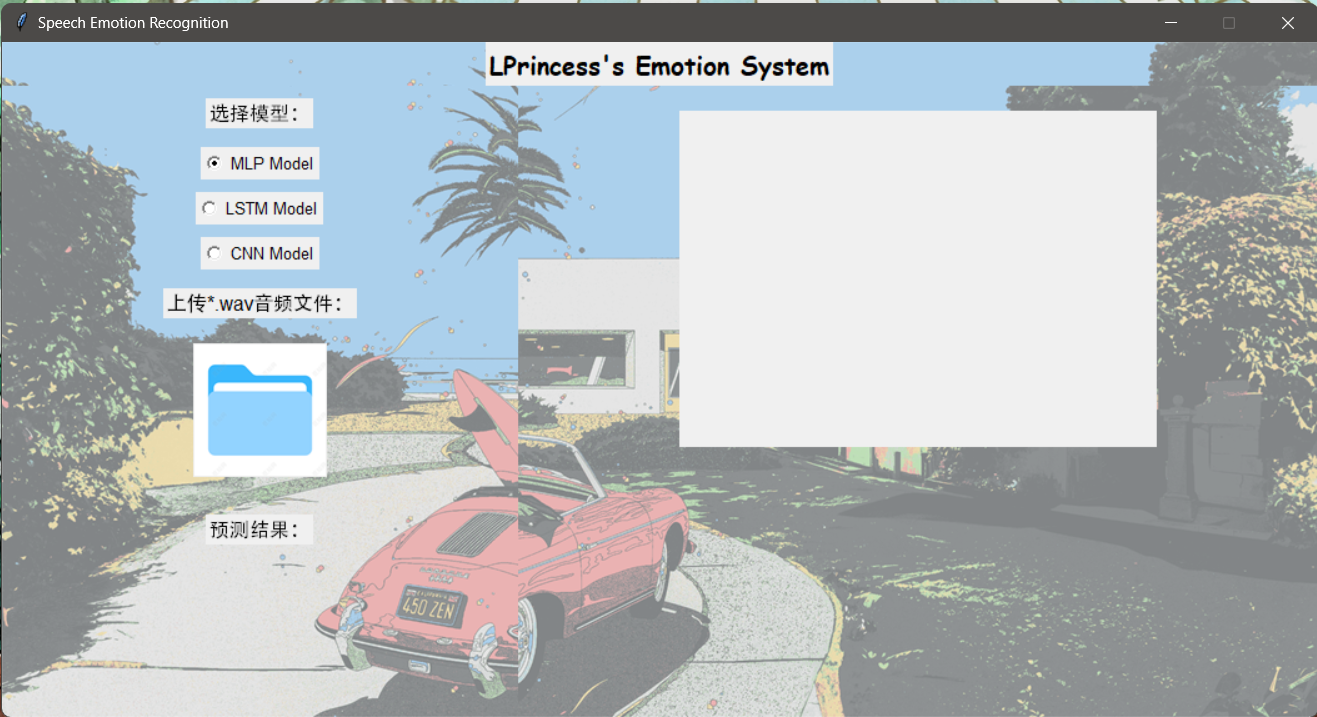
0x05应用——UI设计
使用Python的Tkinter库创建的图形用户界面应用程序,旨在进行语音情感识别。应用程序能够加载音频文件(.wav格式),提取其MFCC(梅尔频率倒谱系数)特征,然后使用预训练的模型(如MLP、LSTM或CNN)进行情感分类,并展示分类结果及其概率。
主要元素:按钮——打开想要测试的音频文件
分类功能:对传进来的文件,先进行mfcc特征提取,这些特征代表声音的短期功率谱。再 用预先导入的模型进行预测,最终显示分类结果。
- 模块导入与模型加载:
- 导入所需的模块和库,如Tkinter, PIL用于图形界面,LibROSA用于音频处理,joblib用于加载模型等。
- 加载预训练的情感识别模型(MLP、LSTM、CNN)以及一个标准化器。
- 功能定义:
- extract_mfcc(wav_file_name): 提取给定音频文件的MFCC特征。
- plot_waveform(audio, ax, canvas_agg): 绘制音频波形。
- plot_mfcc(audio, sr, ax, canvas_agg): 绘制MFCC特征。
- classify(): 这是主要功能,用于打开文件对话框以选择音频文件,提取MFCC特征,使用所选模型进行情感识别,并更新UI以显示结果。
- img_transparent(image_path, transparency_level): 用于创建透明图像。
- 界面构建:
- 使用Tkinter构建应用程序界面,包括左侧的模型选择区域和右侧的绘图区域。
- 左侧包括模型选择的单选按钮(MLP, LSTM, CNN),上传按钮和结果显示区域。
- 右侧用于显示音频波形和MFCC特征图。
- 事件绑定: 将上传按钮绑定到classify()函数,当用户选择音频文件时,应用程序将执行分类并更新结果。
运行截图:
0x06 文本情感分析
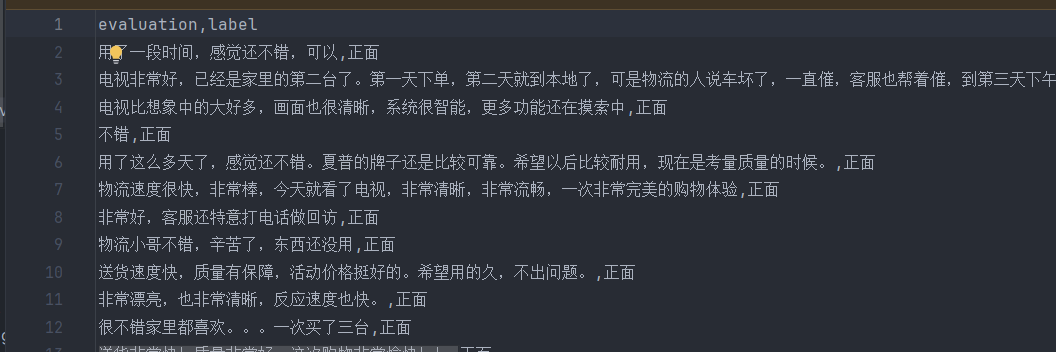
数据集——语料库
以某电商网站中某个商品的评论作为语料(corpus.csv),点击下载数据集,该数据集一共有4310条评论数据,文本的情感分为两类:“正面”和“反面”,该数据集的前几行如下:
数据集分析
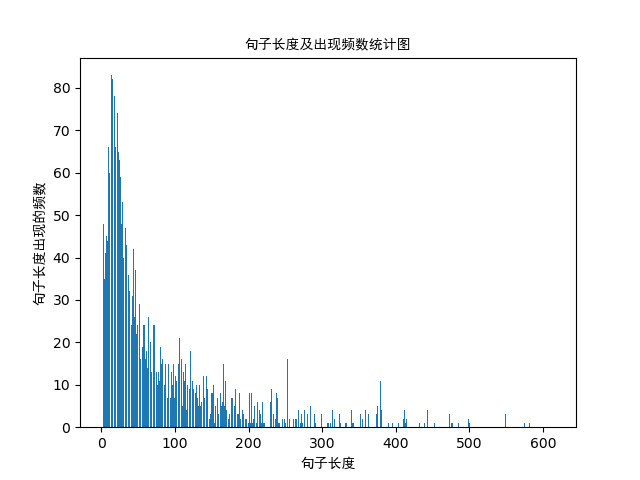
数据集中的情感分布;数据集中的评论句子长度分布
句子长度及出现频数统计图如下:
句子长度累积分布函数图如下:
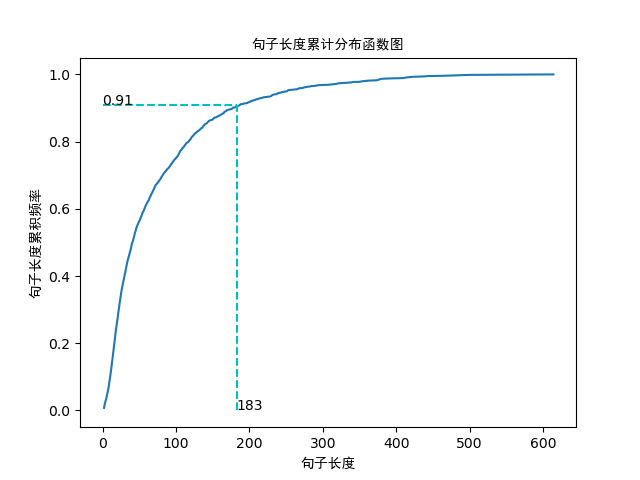
从以上的图片可以看出,大多数样本的句子长度集中在1-200之间,句子长度累计频率取0.91分位点,则长度为183左右。
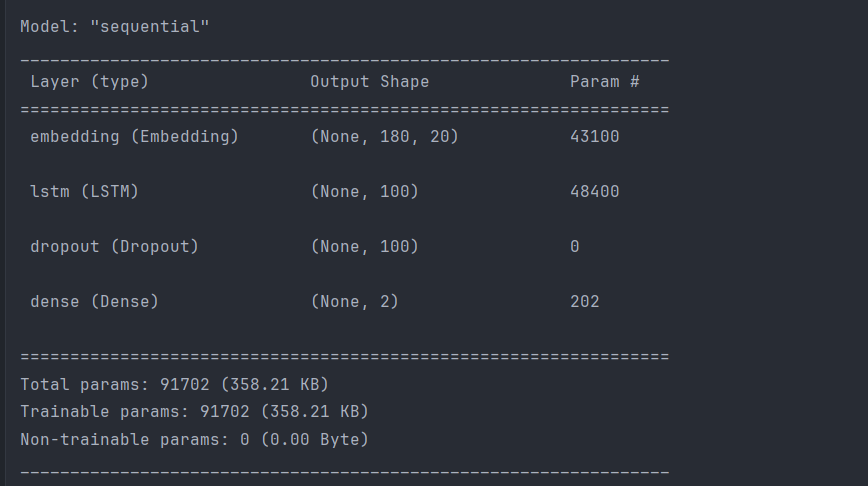
LSTM——训练
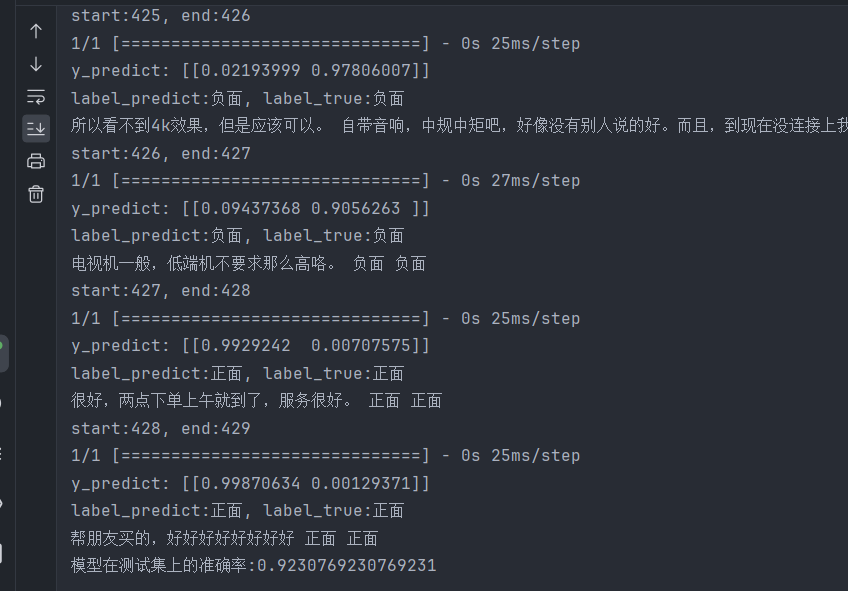
网络结构:
问题
问题1
单单语音文本训练效果并不理想,训练次数多了容易过拟合,少了精度不高,因此加入文本情感分析
问题2
使用to_categorical时,单单from keras.utils.np_utils import to_categorical会报错
需要导入完整路径from tensorflow.python.keras.utils.np_utils import to_categorical
参考文献
- http://blog.lprincess.top/Development/emotion.html
- https://www.kaggle.com/code/asaifali/speech-emotion-recognition/notebook
- https://www.kaggle.com/code/darsh04/audio-classification-lstm
- https://www.kaggle.com/datasets/uwrfkaggler/ravdess-emotional-speech-audio/data
- https://github.com/Divyansh-Devrani/SPEECH-EMOTION-RECOGNITION-USING-PYTHON-AND-RAVDESS/blob/main/SER-PROJECT/sound.py
- https://github.com/jujimeizuo/Music_Label
- https://zhuanlan.zhihu.com/p/104577908
- https://blog.csdn.net/winone361/article/details/96705119
- https://blog.csdn.net/m0_54510474/article/details/124385710
- https://zhuanlan.zhihu.com/p/32085405
- https://blog.csdn.net/hxxjxw/article/details/108196295
- https://www.kaggle.com/code/shivamburnwal/speech-emotion-recognition/notebook