ComfyUI
ComfyUI配置
git clone https://github.com/comfyanonymous/ComfyUI
因为之前已经装过sd-webui,并且想复用它的大模型,则可以先找到..\comfy-UI\extra_model_paths.yaml.example这个文件。首先去掉.example后缀然后用任何你喜欢的文本编辑器修改这个文件。找到a111,修改base_path,改为你实际的webui安装路径(此例中我的webui在..\sd-webui-aki-v4.9下)
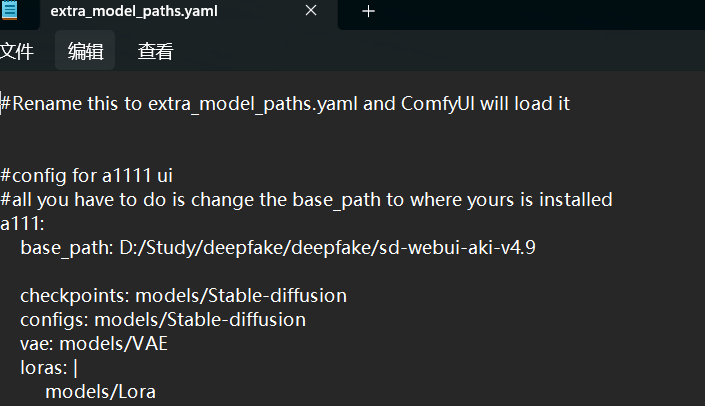
注意,base_path的冒号后面有个空格,斜杠方向采用linux标准,哪怕是在windows下用也必须用linux格式的路径。
ComfyUI核心模块
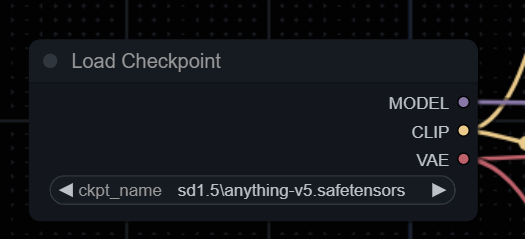
模型加载器(Load Checkpoint):Load Checkpoint用于加载基础的模型文件,包含了Model、CLIP、VAE三部分。可以简单理解为在这里放训练好的模型文件。
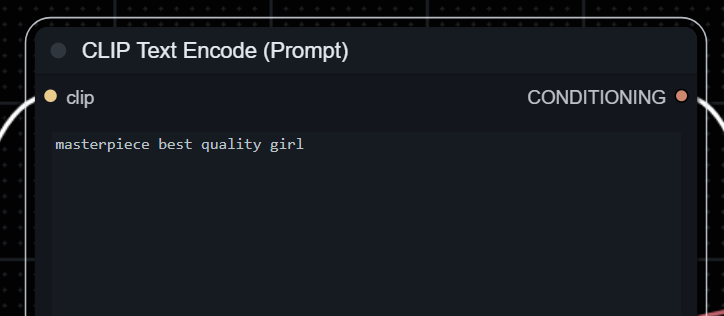
CLIP模块:CLIP模块将文本类型的输入变为模型可以理解的latent space embedding作为模型的输入。可以简单理解为这里是输入提示词的地方(正向和负向提示词。比如在绘图过程中大模型总是画不好手,你可以在负向提示词那一栏里加上一句:模糊扭曲的手
采样器:用于控制模型生成图像,不同的采样取值会影响最终输出图像的质量和多样性。采样器可以调节生成过程的速度和质量之间的平衡。
KSampler 使用提供的模型以及正负条件来生成给定 latent 的新版本。首先,根据给定的种子和降噪强度对潜图像进行噪声处理,擦除一些潜图像。然后,使用给定的模型和正负条件作为指导来去除这些噪声,在图像被噪声擦除的地方“构思”新的细节。
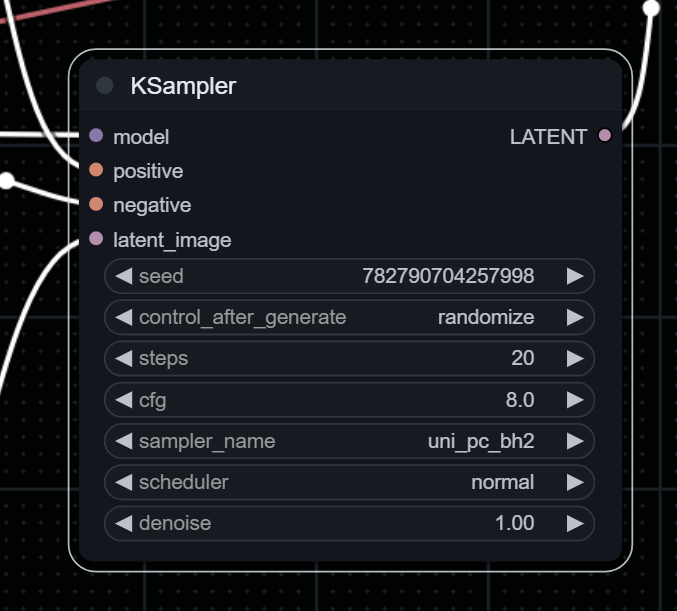
| Input | Function |
|---|---|
| Model | 用于降噪的模型 |
| Positive | 积极的条件反射 |
| Negative | 消极条件反射 |
| latent_image | 将被去噪的 latent |
| seed | 控制噪声产生的随机种子 |
| control_after_generate | 控制seed在每次生成后的变化 |
| steps | 降噪期间要使用的步骤数。允许采样器进行的步骤越多,结果就越准确。相对的生成时间也越长。请参阅 samplers 页面,了解有关如何选择适当步骤数的良好指南 |
| cfg | classifier free guidance决定了prompt对于最终生成图像的影响有多大。更高的值代表更多地展现prompt中的描述。 |
| sampler_name,scheduler | 降噪参数,请参阅 samplers |
| denoise | 多少内容会被噪声覆盖(使用小于 1.0 的降噪值, 这样,原始图像的某些部分在被噪点时被保留下来,从而引导去噪过程到外观相似的图像。) |
解码器:VAE模块的作用是将Latent space中的embedding解码为像素级别的图像。简单理解就是出图片的区域。
局部重绘
在WebUI中通常选择用涂抹重绘区域的方式来让AI知道要重绘哪里,这个被涂抹的区域会被AI识别为黑白区域,白色的部分也就是所谓的重绘蒙版“遮罩”。
参考链接
- https://blenderneko.github.io/ComfyUI-docs/Core%20Nodes/Sampling/KSampler/
- https://blog.csdn.net/ki1381/article/details/140646684